





Група вчених із Німеччини повністю розшифрувала геном неандертальця

Про це пише техноблог Slashgear.com.
Ще у 2010 році німецькі вчені на чолі з доктором Сванте Пеебо, співробітником інституту еволюційної антропології Макса Планка (Лейпциг), секвенували геном цього виду людей на основі кісток трьох європейських неандерталок, які жили близько 40 тис років тому.
Натомість, зараз геном реконструювали на основі 0,038 грамів скам'янілого фаланга пальця стопи, виявленого в Денисовій печері на півдні Сибіру.
ЧИТАЙТЕ ТАКОЖ: Вчені навчились зберігати сонети Шекспіра на молекулах ДНК
Пеебо стверджує, що отриманий геном більш точний, ніж "хорватський". За сукупністю всієї спадкової генетичної інформації організму видно, що цей неандерталець був близький з іншим представником того ж виду в Європі і Росії.
"Якість генома дуже висока, його можна зіставити з якістю генома Денисівської людини, секвенуваної у минулому році, і, можливо, навіть кращою, ніж доступні нам геноми сучасної людини", - заявив ще один автор дослідження, доктор Кай Прюфер.

Фото: slashgear.com
"Зараз ми збираємося порівняти геном цього неандертальця з геномом Денисівської людини, а також з "чорновими" геномами інших неандертальців. Це допоможе нам краще зрозуміти, що змінилося в геномі сучасних людей після того, як вони відокремилися від предків неандертальців і Денисівських людей", - пояснює Пеебо.

Сванте Пеебо розглядає геном неандертальця. Фото: paleorama.wordpress.com
Хоча наукова публікація за даними дослідження вийде лише за кілька місяців, вчені вже виклали геном у вільний доступ, щоб поділитися ним з іншими дослідниками неандертальців.
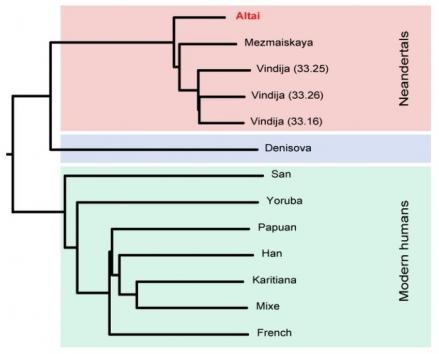
Фото: paleorama.wordpress.com
Автори дослідження також нагадали, що перші - часткові - результати цього дослідження були опубліковані в листопаді 2006 року. Вченим вдалося ізолювати спадковий матеріал неандертальця з кісток, знайдених в Хорватії. Їх вік - близько 38 тисяч років.
Аналіз був пов'язаний з неабиякими труднощами, оскільки молекули ДНК зазвичай нараховують близько 3-х мільярдів нуклеїнових основ, які впродовж тисячоліть розпалися на фрагменти завдовжки у близько 50 основ.
Кожну з букв генетичного коду вчені прочитали у середньому лише один раз. Зазвичай для мінімізації помилок секвенування проводять доти, доки весь код не буде прочитаний багаторазово, проте в даному випадку дослідники застосували нову технологію, здатну і за одноразового прочитання забезпечити цілком прийнятну для робочої версії точність.
Аналіз отриманих даних дозволив, зокрема, відповісти на питання, чи мало місце змішання між неандертальцями і предками сучасної людини.










